
As a follow up to my prior post on single-motherhood and mobility and in response to various assertions of discrimination against blacks in the school system, I decided to take a data-driven look into the relationship between race and school suspension rates.
There is, of course, ample evidence that discipline rates vary dramatically between racial/ethnic groups.
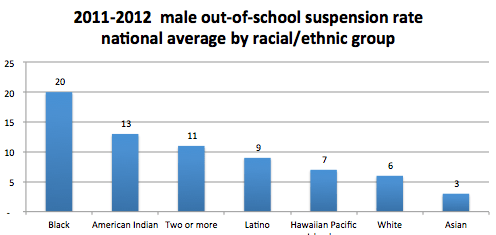
Blacks get suspended at vastly disproportionate rates whereas “asians” (census/OMB definition), on the other hand, are about half as likely as whites are to get suspended. Contrary to conventional wisdom, though, this pattern tends to be pretty consistent nation wide and the south is not notably “worse” with respect to disparities here.
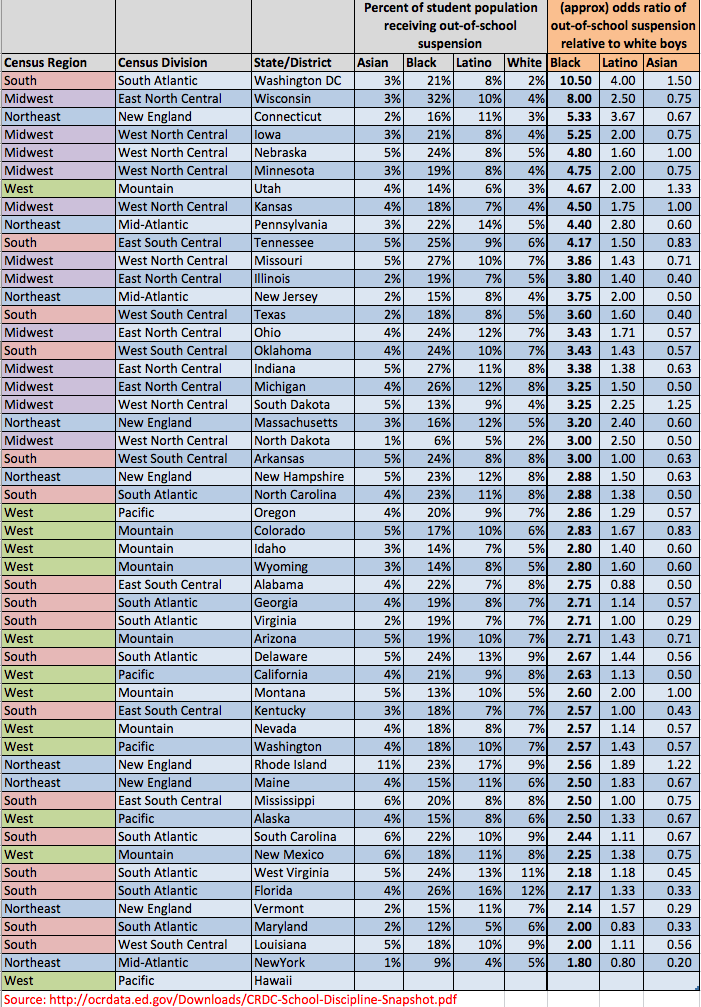
The main thing that differentiates the south are demographics. 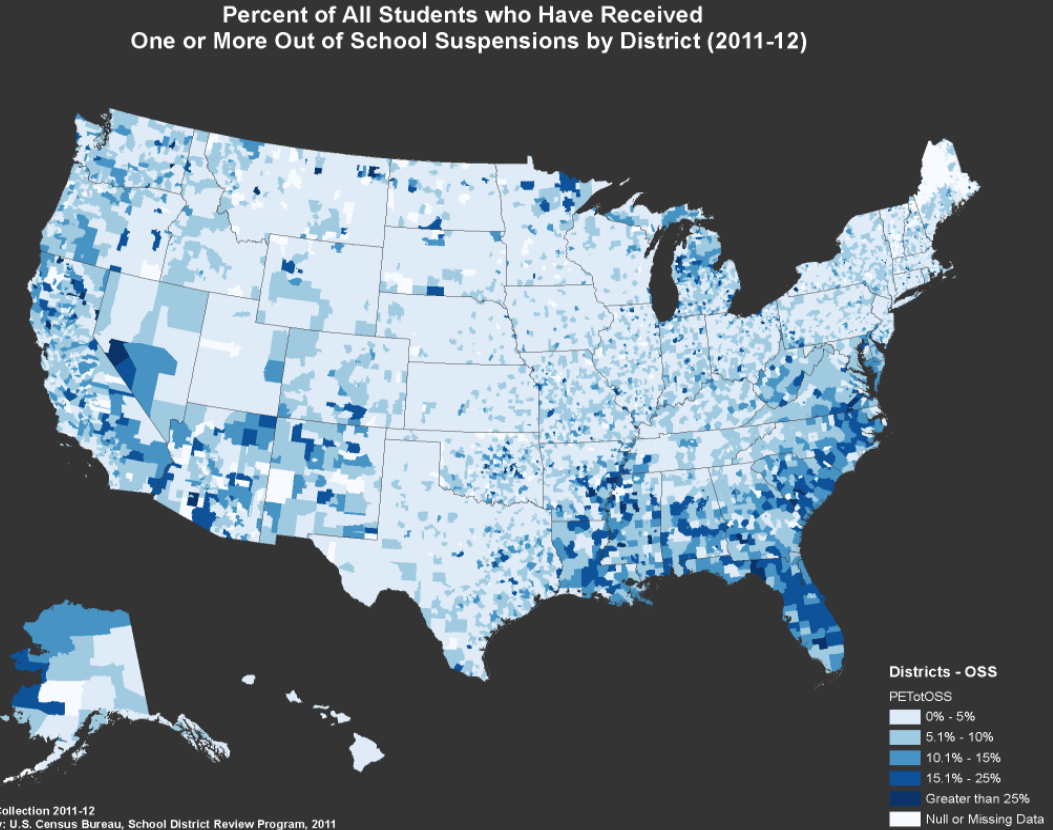
There are simply far more blacks proportionally in the south and schools there are much more likely to be majority black.
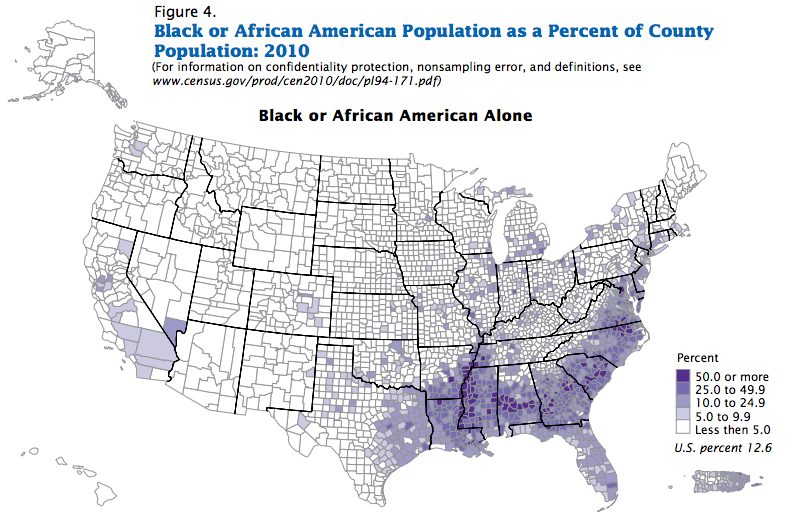
Thus these sorts of infographics tend to be highly misleading:
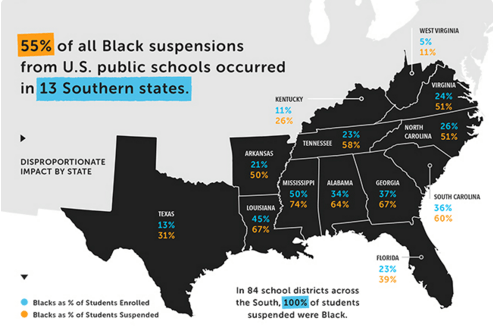
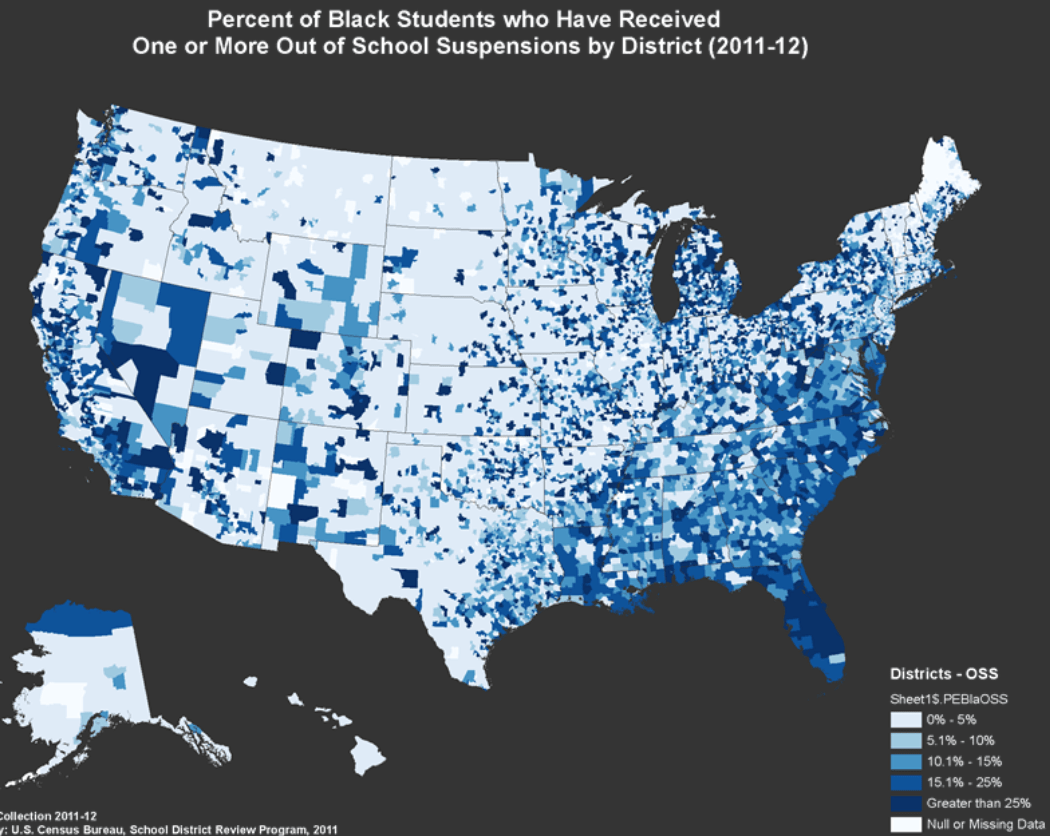
If you actually look at the department of education’s own map you will see very little sign of regional bias in places with significant concentrations of blacks. If anything the disparities (without adjusting for anything), tend to be larger in the northeast and the midwest (see table above).
There is a strong, near linear, relationship between percent of school district black and the overall suspension rates. 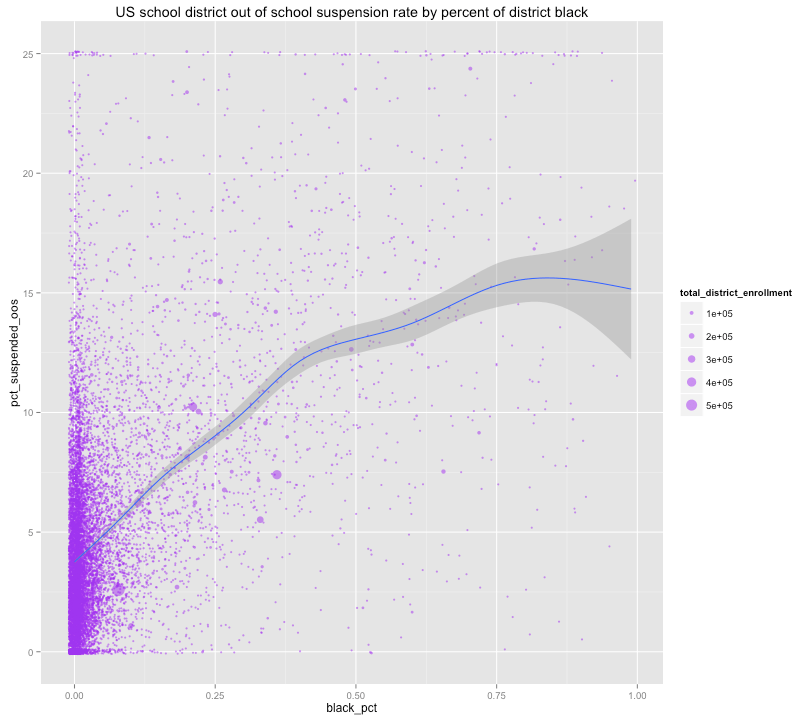 [note: no adjustment for grades offered, locale, district type, and more. Also the data is top coded at 25% for some reason… which may skew the top predictions down a bit]
[note: no adjustment for grades offered, locale, district type, and more. Also the data is top coded at 25% for some reason… which may skew the top predictions down a bit]
Schools with higher proportions of black students (chosen at random) are more likely to have appreciably more discipline citations. This tends to suggest that this is a broad national pattern and that racial demographics accounts for much of the variance.
If we look at this instead by suspension rates of black students only, we see a bit of trend, but not a huge one:

(note: the red line here is a weighted linear regression, the blue is an unweighted linear regression…. too sparse for weights)
This despite the fact that these mostly black districts are much more likely to be populated with black teachers, principals, etc (unfortunately I don’t have national data at this level of detail!). If these suspensions are mostly grounded in real behavioral problems, as I suspect they are, they are likely to have negative consequences for other students in the classrooms (especially other blacks since they are far more likely to be in class with the misbehaving students).
If we plot the black suspension rate directly by percentage of single-mothers in the school district (all races/ethnicities)…

(note: the red line here is a weighted linear regression, the blue is an unweighted loess regression…. too sparse for weights)
Here we can to see a much clearer and generally more plausible pattern. Keep in mind that the x-axis is the rate for all groups in the district, which is imperfectly related to the actual rate for blacks, and that the y-axis is top coded at 25% again.
If I plot it against the black single-motherhood rate, potentially including some black hispanics (not a perfect match w/ y-axis, but ACS tool won’t let me fetch that table right now), I get something like this:

That looks pretty noisy. If I subset the districts to capture only those districts with > 1000 blacks students (because: more reliable ACS estimates, less noise in the suspension rate data) and that are local school districts (no charters), it cleans up a good bit.

Annoyingly I’ve yet to find a decent way to get non-hispanic white suspension rates for all districts from them yet, but it is nonetheless quite obvious that the single-motherhood rate is a strong predictor across the country.


It predicts overall suspension rates better than percent black, better than (child) poverty rates, better than parent education rates (% w/ bachelors+), and so and so forth.

Even if I filter to exclude relatively small districts (<10K):
 Likewise, if I run a loess regression against single-motherhood on the entire data set to make predictions using single-motherhood alone and then split up the districts by percent black, you can pretty clearly see that the slope doesn’t much change. A 1 SD increase in single-motherhood based loess prediction is equal to more than a 0.5 SD expected increase is suspension rates.
Likewise, if I run a loess regression against single-motherhood on the entire data set to make predictions using single-motherhood alone and then split up the districts by percent black, you can pretty clearly see that the slope doesn’t much change. A 1 SD increase in single-motherhood based loess prediction is equal to more than a 0.5 SD expected increase is suspension rates.

Black has still has some residual power in this bivariate loess regression, but we can pretty clearly see that it predicts quite independently of percent black and, in fact, isn’t much different until we reach the top decile.
Likewise, if we flip this plot around a bit and predict with percent black….

We can see that, at least at low levels of single-motherhood (the bottom few regression lines), the slope is pretty minimal. (keep in mind that the absolute range increases here significantly at higher deciles and that the predicted effect is larger there too).
Linear modeling exercises.
Linear model with race
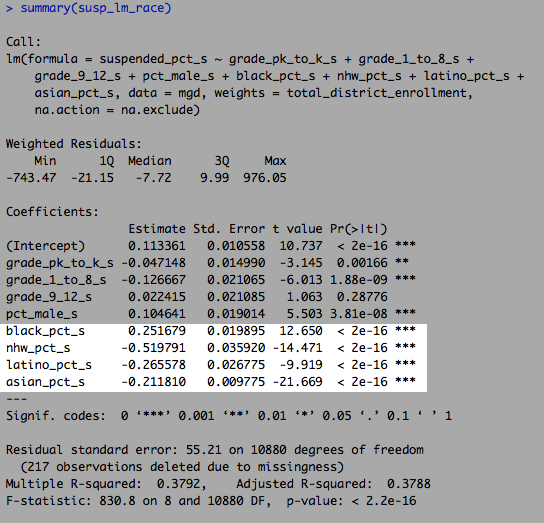
However, if I just add single-motherhood into the model the difference is cut in half.
linear model with race plus family structure
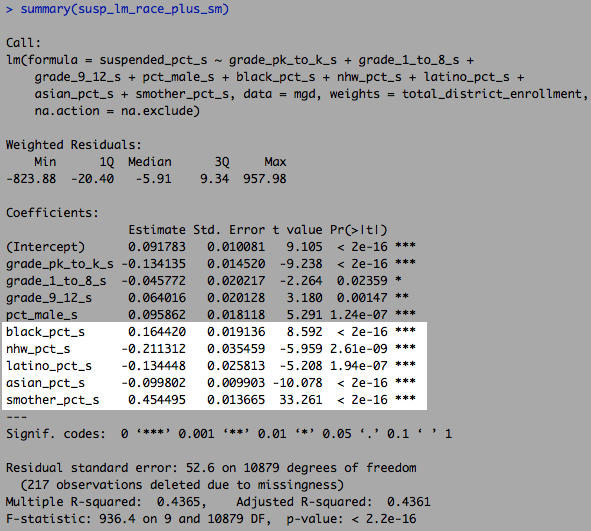
If I add further controls for SES (mean family income and proportion of parents with bachelor degrees or higher)….
linear model with race plus family structure plus SES
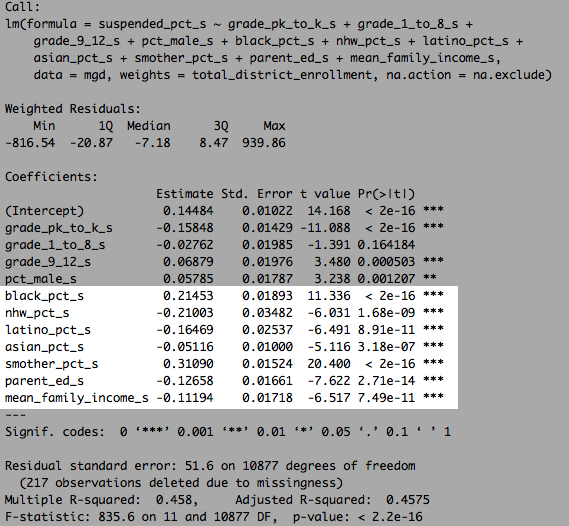
Or add poverty rates to that….
linear model with race plus family structure plus SES (plus poverty rate)
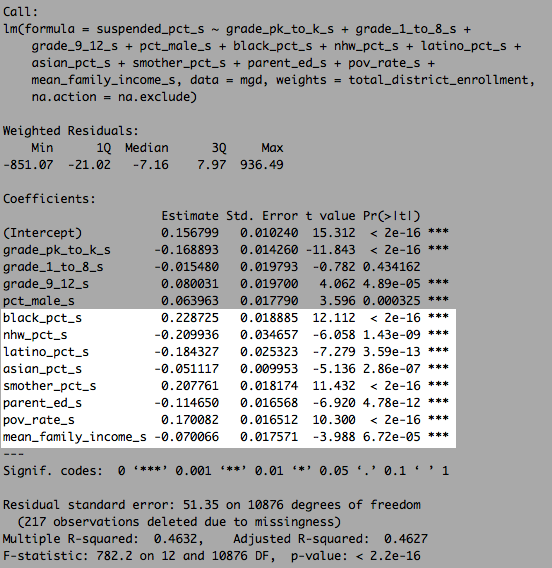
The single-motherhood coefficient is reduced somewhat by the addition of poverty rates, but it still remains significant and likely plays a non-trivial role in shaping the poverty rate itself because single-mother households, in particular, are much more likely to end up in poverty (perhaps I’ll try SEM later).
There is a good chance that if I were to add more variables to equation the black coefficient would shrink even further, especially with something like test scores, but I thought I’d try to keep this relatively simple, lest I be accused of “over-controlling”.
It’s also worth noting that the relative differences in (unscaled) coefficients for major racial/ethnic groups produced here are pretty similar to aggregate differences in the rates nationally, i.e., this method seems to be resolving patterns in suspension rate differences even though it’s working with aggregates and the like.
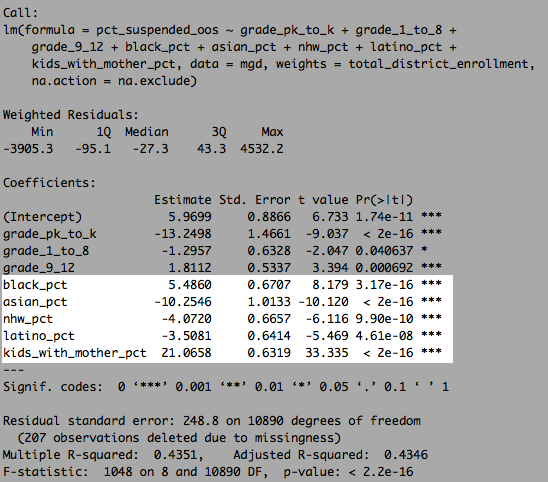
Single-motherhood also predicts aggregate differences between major racial/ethnic groups quite well.

You might note that latinos/hispanics occupy a very different spot on this plot than if you were to try to do so with, say, family income or poverty rates (which is very similar to blacks nationwide).
Or by state (albeit with single-parents instead of “mothers”): 

(Note: I fetched this data from “Kids count” because the ACS tool is too much of a PITA for this right now. Unfortunately they combine “asian” and pacific islanders into a single group and single-parent is a bit different than single-mothers. Good enough for now though….).
Different states likely have somewhat different thresholds for behavior and different discipline policies, but you can still see a pretty consistent relationship within most states. You might also note that states with very large differences in single-motherhood rates tend to be the furthest apart in suspension rates (and various other outcomes) too.
Even single-parenthood rates between states, but within ethnic groups, explains a good bit of the differences in suspension rates (especially for whites and blacks).
In fact, if you project the white regression line for states with significant black populations, you’ll find that the black points intersect the projection quite well (and mostly vice versa for blacks, though it’s noisier).

That is about all I have for now.
I am deeply skeptical of the notion that racial discrimination explains much of the differences in outcomes here, particularly when we observe such vast differences in strong predictors like single-motherhood and see similar patterns with other racial-ethnic groups (even when it works against whites, as in the case of “asians”). Now it may be that single-motherhood is operating mostly as a proxy for other differences, but there is some evidence that it is more than that (or see here for more info). Regardless, it seems unreasonable to leap to the assumption that differences in outcomes are the fault of racism on the part of teachers, administrators, and the like when we have good evidence that the outcomes can be mostly explained with readily available observables like this (even more so when it’s quite widely known that there are substantial statistical differences in behaviors between groups today).
I’ll be updating with code and data later (probably should have proofread this more too! 🙂
P.S., In anticipation of the objection that Europe has even higher birth out-of-wedlock rates, I’ll just point out that (1) I’m (mostly) measuring single-parenthood here (2) the (causal) effect is presumed to come from actual living arrangements/parental involvement, and (3) that the United States is actually quite a bit worse off than most other highly developed countries in this regard. To wit, see this plot I generated from OECD data earlier today.
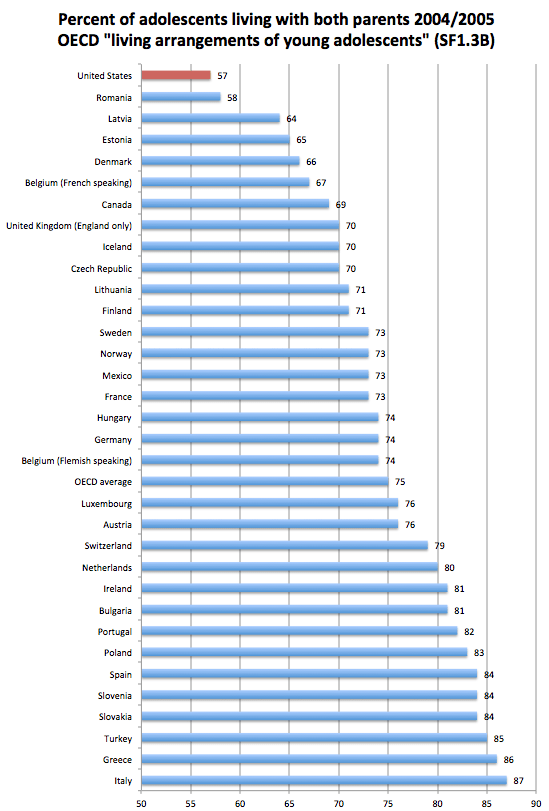
Different countries have different marriage patterns today, but the significance of those patterns isn’t the same with respect to parenting and the like.
What source did you use to get the single motherhood rate by school district?