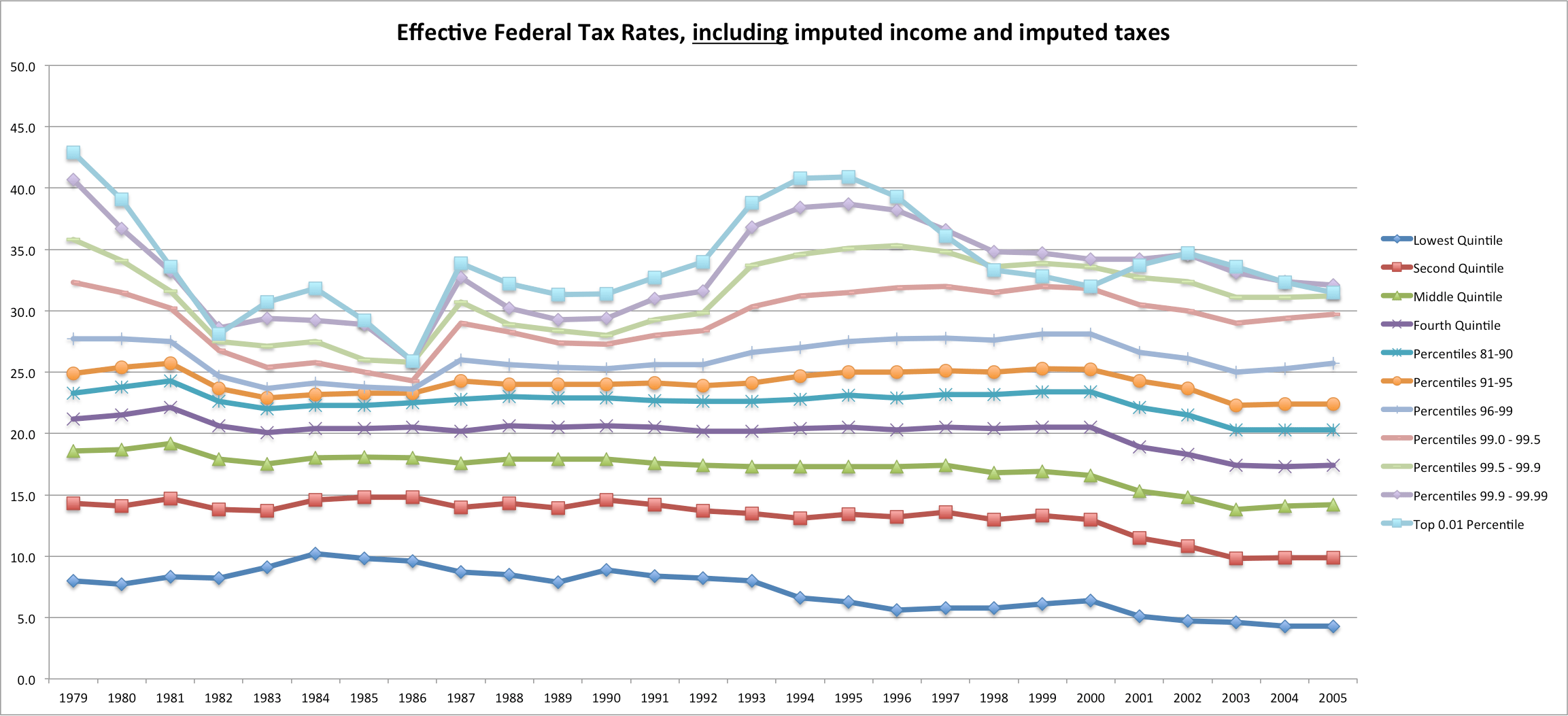
The Congressional Budget Office periodically produces income distribution and effective tax rate data for households by income group.
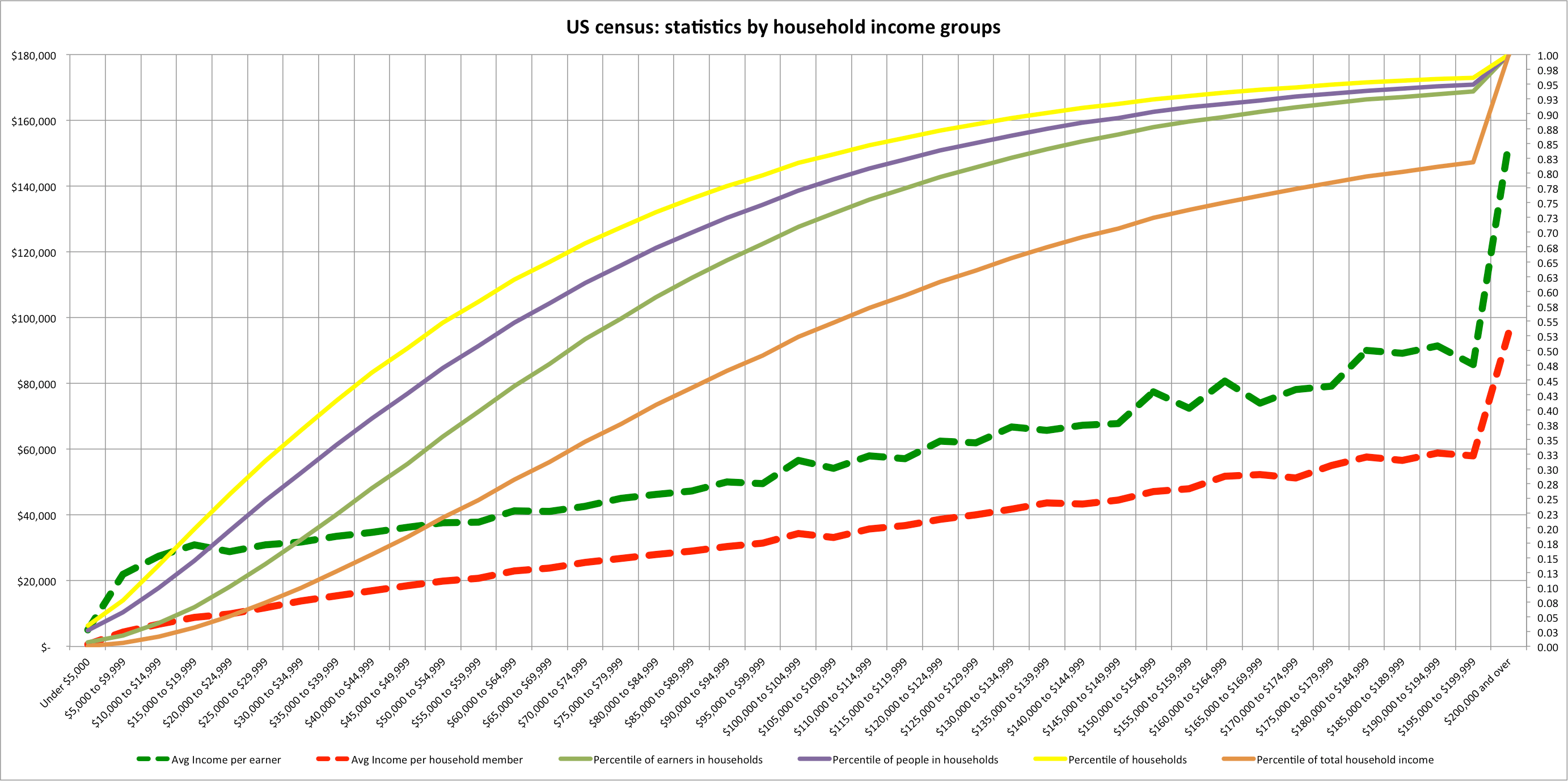
One interesting, but little known fact, is they produce their “income categories” (quintiles, top 1%, etc) with a weighting according to the household size.
Here is their definition:
“Income categories are defined by ranking all people by their income adjusted for household size—that is, divided by the square root of a household’s size. (A household consists of the people who share a housing unit, regardless of their relationships.) Quintiles, or fifths, contain equal numbers of people, as do percentiles, or hundredths. Households with negative income (business or investment losses larger than other income) are excluded from the lowest income category but are included in totals.“
What this means is that a household with 1 person and 50K of income would be ranked identically to a household with 100K of income and 4 people, as would a household with 150K in income and 9 people, and so on.
Although I think this is, in some respects, a useful and perhaps necessary way of approximating the welfare of each individual household, I suspect they unintentionally mislead a lot of people with respect to both the effective tax rates and the actual distribution of income since few people probably know that they do this in the first place and fewer still understand the implication of this.
Consider, for instance, that if the wealthiest 0.5% of households (unadjusted for size) adopted 1 child each, it would surely produce a more “unequal” distribution since highest reaches of the income distribution would account for that much more of the population (CBO income groups always account for similar shares of the entire population), despite the fact that they have less discretionary income and haven’t (for the sake of argument) increased their incomes by one dime.
The CBO further confuses this issue by then quoting the average income, pre- and post- tax, across these adjusted-income groups without actually quoting the adjusted-incomes (which seems very strange to me indeed). Thus, say, middle 20% of households may shrink dramatically in size and may include people with very different raw-income levels, but their published results do not give you any hint of this at all.
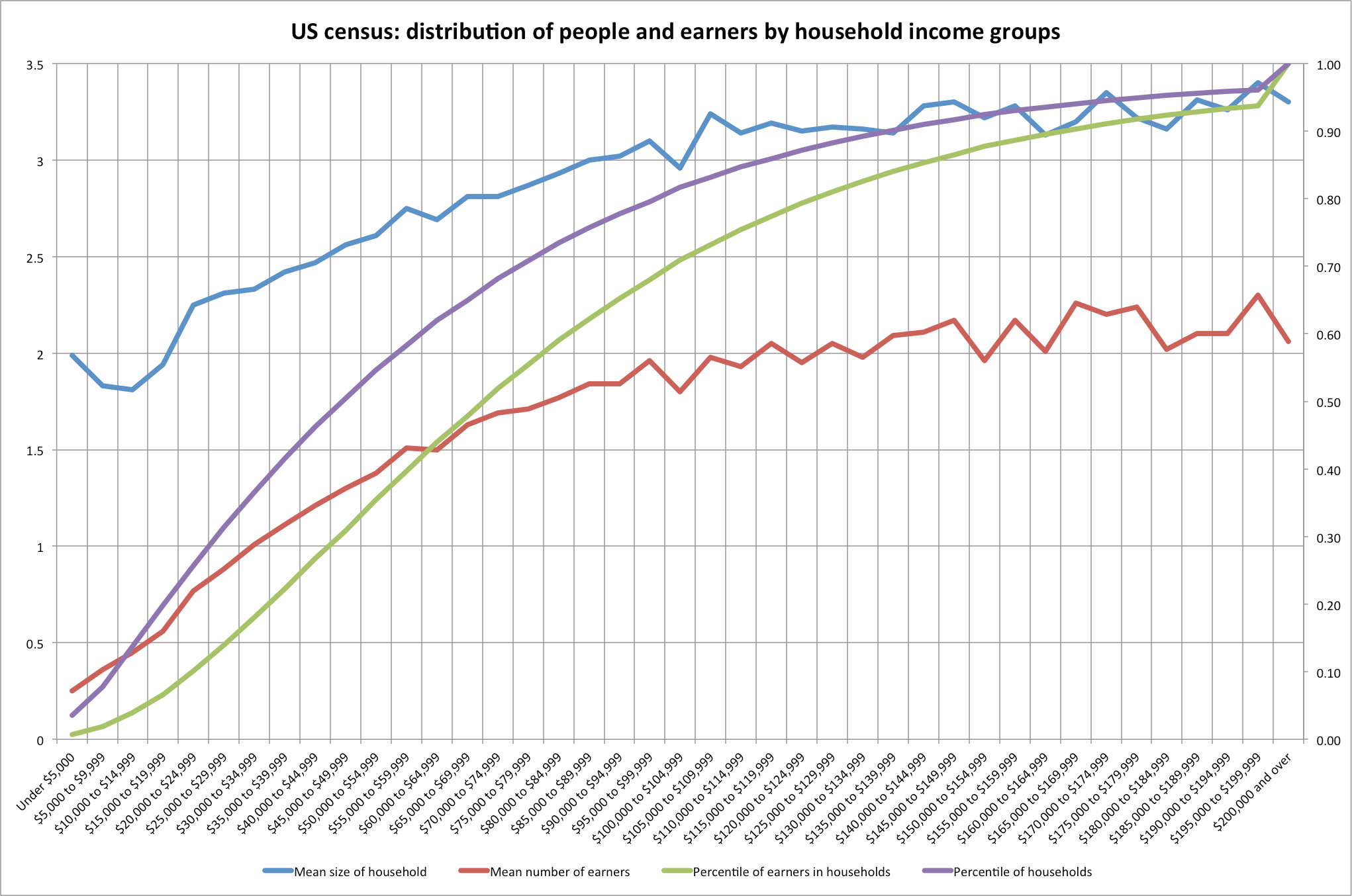
This is not an academic argument since, in fact, the households have never been identically sized and there has been a significant shift in the distribution of population (and, in fact, earners) amongst the households.
Below I have calculated the approximate size using their household count data (they round the numbers so there is a small amount of error between years).
Average number of people per CBO household income group (scaled to 1979)

Observation: The very richest and very poorest grew or stayed the roughly the same, whereas the middle income groups and the like dropped dramatically in size. (Remember: this is after their weighting method so “middle” can mean very different pre-weighted incomes… the effects are probably even more dramatic w/o this weighting)